A Tale of Two Models
Image reasoning in action
I’ve written about the difference between 4o and o3’s ability to analyze images, but I want to give an example from a current participant in You & AI. Tom is a professor, and his work involves studying 19th century maps. He shared this fragment of a map with me:
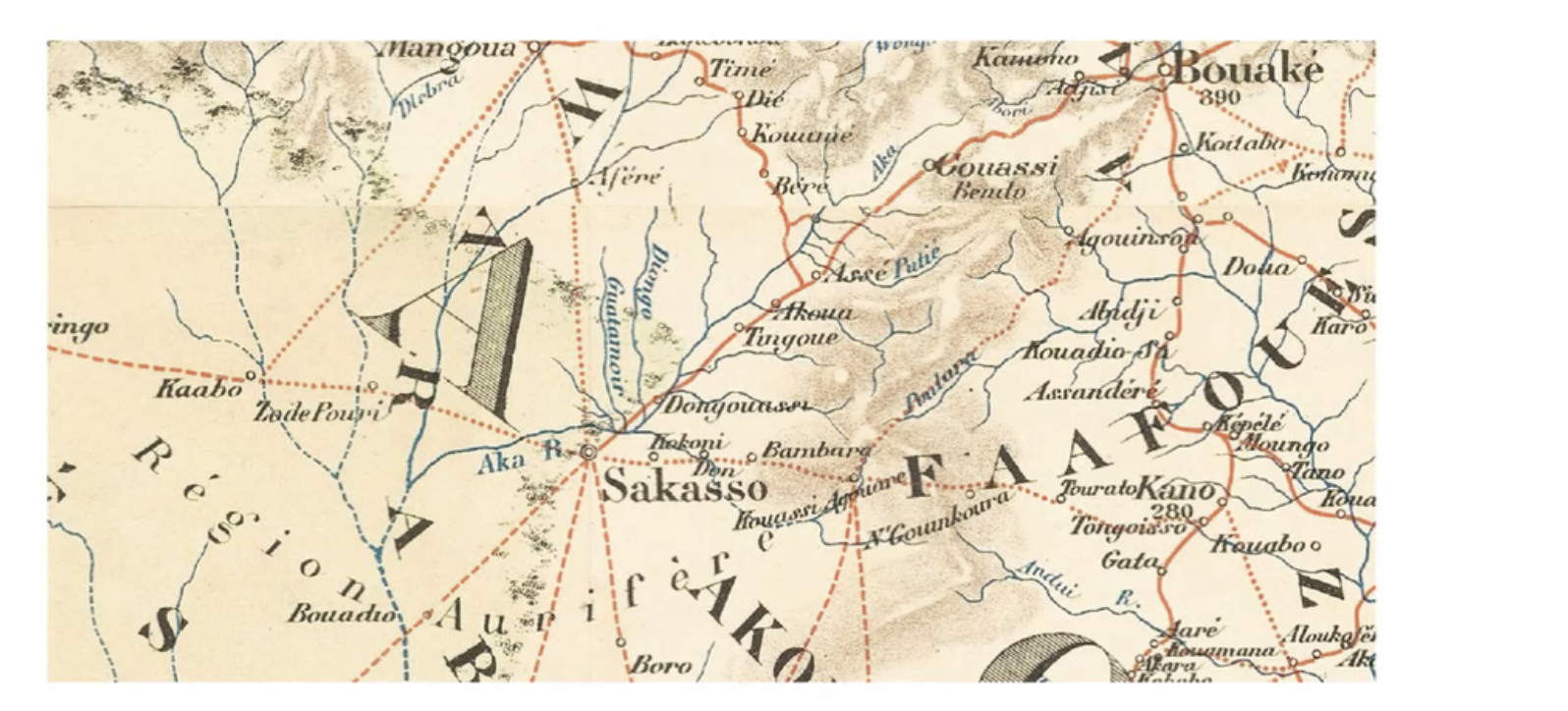
Fragment of a vintage map
When I asked 4o to tell me what it knew about the map, it almost instantly–and entirely incorrectly–located the fragment in Berkeley, California in the 1930-1950 period:

4o model’s analysis of the map fragment
Then I gave the same prompt to o3. This time, the model took over three minutes, carefully analyzing it before concluding the fragment was likely a region of Côte d’Ivoire, from 1894 to 1908. It was right. The map is, in fact, an 1894 French map from Côte d’Ivoire.


Alongside the map, ChatGPT offered an analysis of various features of the map, and the politics implicitly guiding it, including boosterism for a gold industry that didn’t exist yet and the omission of many of the villages on the Central Plains. The o3 model didn’t just read the map, it read the map. It summarized:
